

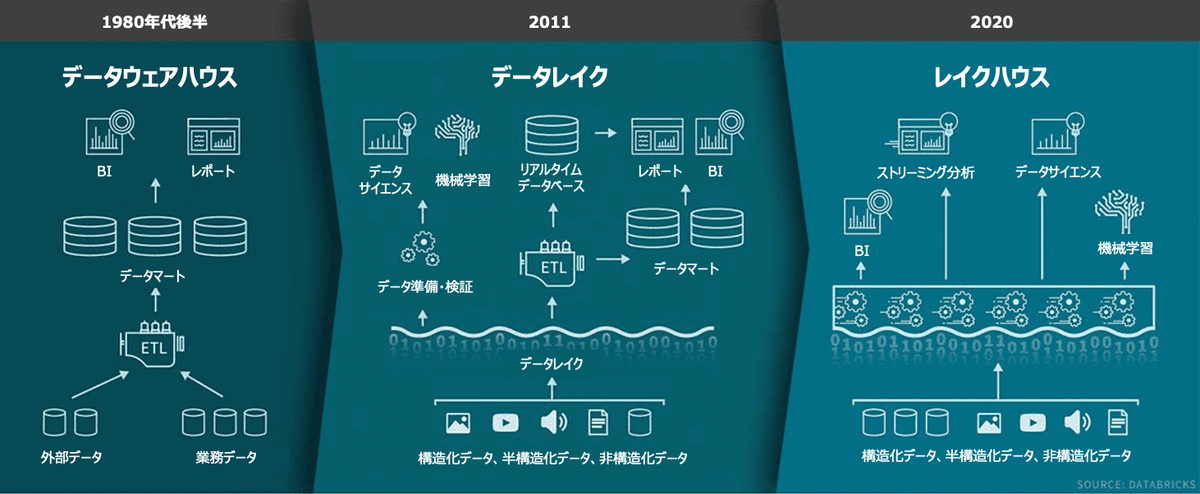
データウェアハウス(第一世代データ基盤)
データウェアハウスは、ビジネス意思決定のためにデータを一つの場所に集約・保管し、分析に利用するためのデータ基盤であり、1980年代に考案されました。複数のデータソースからデータを取得してETL処理を行い、データウェアハウスにデータを蓄積していきます。データウェアハウスは、構造化データの処理に適していましたが、非構造化データ(文章や音声、画像など)のようにそのままでは利用できない複雑なデータの処理には適していませんでした。
データレイク(第二世代データ基盤:2層アーキテクチャ)
2000年代に入り、データウェアハウスの課題である非構造化データを分析するニーズが増えたことをきっかけに、データレイクが登場しました。データレイクは、テキストデータや画像、テキストなど構造化データ以外のデータも格納することができ、データ分析や機械学習で利用することができます。しかし、データレイクにはトランザクションのサポートやデータ品質の保証がありません。また、さまざまなデータを自由に格納できる反面、必要なデータが見つかりづらくなり、データスワンプ(活用ができないデータが大量に溜まっている)を引き起す懸念がありました。
データレイクハウス(次世代データ基盤)
データレイクハウスは、データウェアハウスとデータレイクの課題を克服しつつ、それぞれの利点を組み合わせたアーキテクチャになります。構成として、データウェアハウスと類似のデータ構造とデータ管理機能を持ちつつ、オープンフォーマットで低コストのクラウドストレージを利用しています。データレイクハウスは、安価で信頼性の高いオブジェクトストレージが利用可能であるため、最新のニーズに適したアーキテクチャと言えます。
ETLとは?
複数のバラバラなデータを “集めて・揃えて・使える形に変換する” のが ETL。
① Extract(取り出す)
複数のデータソースからデータを集める。
例:
- 売上は「ECサイトDB」
- 顧客情報は「CRM(Salesforce)」
- 広告コストは「Google Ads API」
- アクセスログは「アプリログ」
これをそのままでは バラバラで結びつかない。
② Transform(変換する)
これが ETL の“肝”。
変換では以下をする:
✔ データ形式を揃える(型揃え)
- 日付フォーマットを統一
- 文字列/数値の不一致を修正
✔ キーの統合(ID統合)
- 顧客ID、店舗ID、商品IDなどを揃える
- 例:Salesforceのcustomer_id と EC の user_id を紐づける
✔ 不要なデータ除去・欠損値処理
- 不正データの除外
- NULL の補完
✔ メトリクス用計算
- 売上 = price × quantity
- CVR = conversions / clicks
✔ 正規化・結合処理
- 売上テーブル × 顧客テーブル × 広告テーブル など
→ 変換(T)がなければデータは分析に使えません。
③ Load(格納する)
変換済みデータを
- データウェアハウス(Snowflake / BigQuery / Redshift)
- データレイク(S3 / GCS)
- BIツールのモデル(Power BI / Looker)
などに保存する。
→ 分析やLLMが利用できる “きれいなデータ” になる。
専門用語
データマートとは 特定の業務目的のために最適化された分析用データベース のこと。
例:
- 売上データマート(Sales Mart)
- マーケティングデータマート(Marketing Mart)
- 顧客行動データマート(User Behavior Mart)
特徴:
- すでに整形済み(JOINや加工が済んでいる)
- 分析に必要な粒度にまとめられている
- 分析者やBIツールが使いやすい構造
- 生データより軽くて扱いやすい





