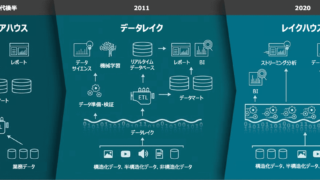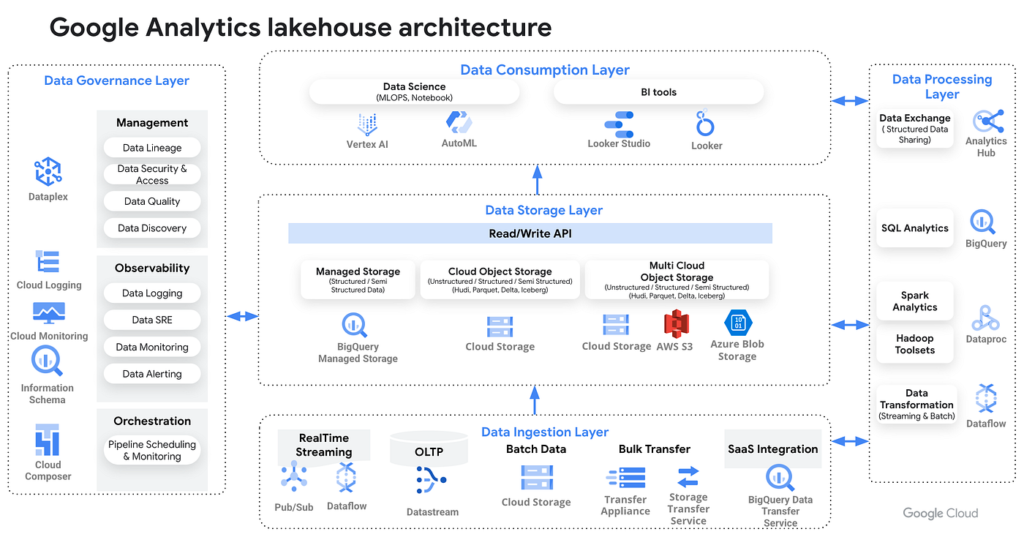
Data Governance Layer
Data Governance Layer は、Lakehouse で管理されるデータに対して
「適切な品質・セキュリティ・カタログ管理・アクセス制御」 を提供するレイヤーです。
組織全体で統一されたデータポリシーを適用し、データの信頼性とコンプライアンスを保証します。
また、メタデータ管理によってデータの探索・分類・系統(リネージ)を可視化し、
分析・AI モデル学習の前提となる データの“信頼性確保” を担います。
主に使用できるサービスは以下の通りです。
Dataplex:
データカタログ、リネージ、データ品質、セキュリティポリシー適用など、
データガバナンス全般を統合的に管理するサービスです。
データレイクと BigQuery のメタデータを一元的に管理し、
自動データ分類(PII 検出)やデータ品質チェックを行うことも可能です。
IAM / Cloud Identity:
ユーザー・グループに対する認可管理を提供します。
BigQuery や Cloud Storage に対して、最小権限で安全にアクセスさせることができます。
BigQuery Row / Column-level Security:
行レベル、列レベルでのアクセス制御が可能です。
機密データに対し、ユーザ属性に応じて可視範囲を制御できます。
Tags / Policy Tags(Dataplex Data Taxonomy):
データ分類タグや機密区分タグを列レベルで付与し、
アクセス制御ポリシーと連動させることができます。
Data Consumption Layer
Data Consumption Layer は、Lakehouse に蓄積されたデータをBI・分析・AI モデル・アプリケーション から利用するためのレイヤーです。
この層では、ユーザーが可視化・レポート・ダッシュボード作成・機械学習モデル構築などさまざまな目的でデータを活用します。また、LLM(大規模言語モデル)や AI サービスを通じた自然言語分析もここに含まれます。主に使用できるサービスは以下の通りです。
Looker / Looker Studio:
可視化ダッシュボードやレポート作成を行う BI ツールです。
LookML を利用したセマンティックモデルにより、
統一指標の管理と高精度なデータ分析が可能です。
BigQuery BI Engine:
インメモリで高速分析を可能にする BigQuery の分析アクセラレーターです。
Looker / Tableau / Power BI と組み合わせて高速なインタラクティブ分析ができます。
Vertex AI:
機械学習モデルの学習・推論、AutoML、LLM (Gemini) などを利用できます。
BigQuery と連携し、特徴量管理や SQL ベースの ML(BigQuery ML)とも統合されています。
BigQuery ML:
SQL だけで機械学習モデルの作成・学習・推論ができます。
データ移動不要で ML ワークフローが完結することが特徴です。
Data Storage Layer
Data Storage Layer では、構造化・半構造化・非構造化データを一元的に保存し、Lakehouse の基盤となる層 です。
ストレージはスケーラブルでコスト効率が高く、データは BigQuery・Spark・AI/ML などさまざまな処理系で利用できます。
メダリオンアーキテクチャ(Bronze / Silver / Gold)でのレイヤリングもこの層に含まれます。
主に使用できるサービスは以下の通りです。
BigQuery(Internal Storage / External Tables):
内部ストレージによる高速クエリ、外部テーブルによる Cloud Storage 連携など、多様な形でデータを扱えます。
Iceberg / Delta Lake / Parquet などのオープンテーブル形式にも対応します。
BigLake:
Cloud Storage 上のファイルを BigQuery の権限管理と統合し、Lakehouseとして利用可能にするストレージレイヤーです。
構造化/半構造化データを統一的なメタデータ管理で扱える点が特徴です。
Cloud Storage:
あらゆる種類のデータ(CSV、JSON、Parquet、画像、動画、ログなど)を保存できるオブジェクトストレージ。
BigLake と組み合わせて Lakehouse のデータレイク部分を構成します。
Data Ingestion Layer
Data Ingestion Layer は、さまざまなデータソースからデータを取得し、Lakehouse に取り込むレイヤー です。
バッチ処理・ストリーミング処理の両方を扱い、データの種類や用途に応じた最適な取り込み方式を選択できます。主に使用できるサービスは以下の通りです。
BigQuery Data Transfer Service:
Google SaaS(Google Ads、YouTube、Campaign Manager など)や外部サービスのデータを定期的に BigQuery に転送するマネージドサービスです。
Storage Transfer Service:
オンプレミスや他クラウド(Amazon S3 / Azure Blob)からの大規模データ移行を行うサービスです。
Datastream(CDC):
Cloud SQL / MySQL / Oracle などから変更データキャプチャ(CDC)でリアルタイムにデータを取り込むためのサービスです。
Pub/Sub:
アプリケーションイベント、IoTデータ、ログなどをリアルタイムに取り込むメッセージングサービスです。
Cloud Data Fusion:
GUIでデータソース接続を管理し、ETL/ELT パイプラインを構築してデータを取り込むことができます。
Data Processing Layer
BigQuery は、Lakehouse Layer 上のデータを SQL によって変換する際の中心的なサービスです。
- ETL/ELT の “T(Transform)” を DWH 内で完結
- ストアドプロシージャ、UDF(ユーザー定義関数)、テーブル関数に対応
- Apache Spark 用のストアドプロシージャにより Spark ワークロードも実行可能
- Remote Function により Cloud Functions / Cloud Run を SQL から呼び出せる → 外部APIやLLMモデルを直接参照するワークフローも実現可能