


セマンティックレイヤーとは、データベースとデータ利用者の間に入り、両者間のやりとりを円滑にする存在です。
通常、データベースにあるデータの利用には、利用者がデータの構造を理解した上で、正確にSQLを書いてデータを取得する必要があります。しかし、データを利用するのはエンジニアやアナリストだけではない今の時代、それらのスキルを全てのデータ利用者に求めるのは現実的ではありません。
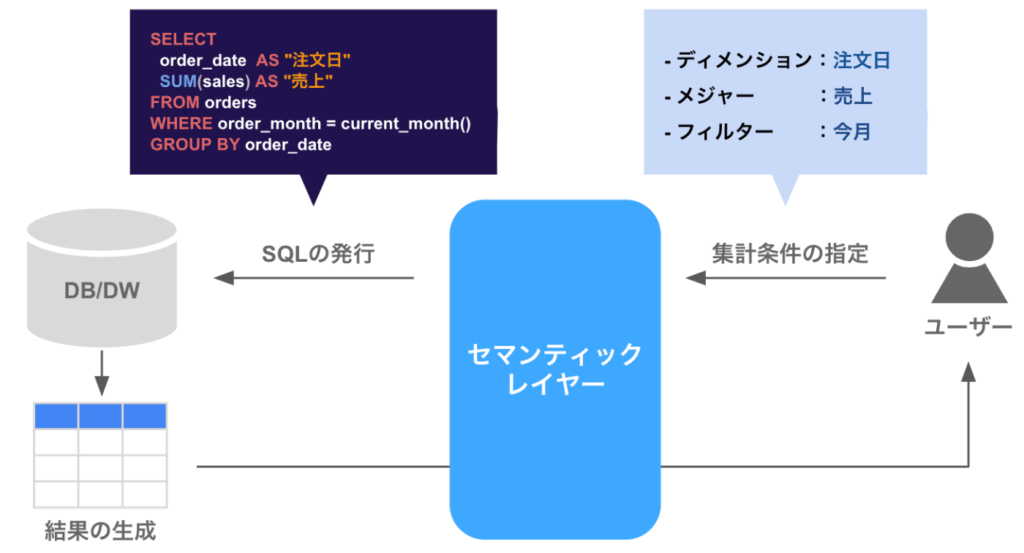
そんな課題を、セマンティックレイヤーは解決します。セマンティックレイヤーを利用すると、データの利用者は「売上」「注文日」などの慣れ親しんだ社内用語をディメンション・メジャー(説明は後述)などに指定するだけで、データを利用できるようになります。セマンティックレイヤーが、指定された条件をもとにSQLを発行してくれるためです。
- ディメンション
日付や顧客名などの、データ集計結果の属性となるもの。SQLではGROUP BYに利用される。 - メジャー
売上や利益などのデータ集計結果に表示される集計された数値。
🔹 役割:指標の「統一」
SLの最も重要な役割は、ビジネスで使用される指標(メトリクス)やロジックの定義を一元化することです。
- 統一されたメトリクス: 「売上」という言葉が、部署によって「粗利売上」だったり「純売上」だったりする混乱を防ぎ、「純売上 = 総売上 – 返品額 – 割引額」のように、その計算ロジックをSL内で明確に定義します。
- 単一の真実(Single Source of Truth): どのBIツール(Tableau、Power BI、Lookerなど)を使用しても、同じ指標に対しては必ず同じ定義と結果が返ってくることを保証します。
- データ構造の隠蔽: ユーザーは、複雑なテーブル結合やSQLを知らなくても、ビジネス用語(例:「顧客単価」「商品カテゴリ」)を使ってデータにアクセスできます。
💡 例え: セマンティックレイヤーは、データの世界における「GPSナビ」のようなものです。ユーザーが「渋谷駅に行きたい」と指示すると(ビジネス用語)、SLがデータベースに「緯度35.6585, 経度139.7016の地点を検索」という最適化されたSQLに翻訳してくれます。
3. 両者の関係と現代のデータ活用
現代のデータスタックにおいて、セマンティックレイヤーはOLAPの概念を実現するための手段として機能します。
🔹 現代のデータスタックにおける位置づけ
従来のOLAPがデータ移動を伴う物理的なキューブ作成に依存していたのに対し、セマンティックレイヤーは、SnowflakeやBigQueryといったクラウドDWHの高速な処理能力を最大限に活用します。
- BIツール: ユーザーが分析リクエスト(OLAP操作)を行う。
- セマンティックレイヤー: リクエストを受け取り、定義されたビジネスロジックに基づき、最適化されたSQLに変換する。
- データウェアハウス(DWH)/データレイク: 変換されたSQLを実行し、結果をSL経由でBIツールに返す。
🔹 V-OLAP(仮想OLAP)による解決
AtScaleなどのV-OLAP(仮想OLAP)ソリューションは、セマンティックレイヤー技術を活用し、物理的なキューブを作成することなく、OLAPが持つ多次元分析の利便性(高速性、一貫性)を実現します。
これにより、データの鮮度を保ちつつ、指標の定義を統一し、高速な分析を可能にするのです。
セマンティックレイヤーはどのようにSQLを作るのか
条件を指定するだけで何故SQLが生成されるのかは、セマンティックレイヤーが保持する情報を考えると理解できます。
セマンティックレイヤーは一般的に、事前に以下のような情報を定義することで構築されます。
- データベースやテーブルに関する基本情報
- 接続に必要な情報(ホスト名や接続方法など)
- データベース上のテーブル名・カラム名
- テーブル間のリレーションシップ
- 各ビジネス用語(売上・日付など)に対する以下の情報
- テーブル上のカラムとの対応関係や計算の定義
- ディメンション・メジャーの分類
セマンティックレイヤーが構築された後は、データの利用者は、主にディメンション・メジャー・フィルターの3つの条件を指定することで、任意の条件でのデータ集計が可能になります。
例えば、以下のような条件を指定します。
- ディメンション:注文日
- メジャー:売上、購買顧客数
- フィルター:2023年のみ
するとセマンティックレイヤーは、事前に定義された情報をもとにして、以下のようなSQLをデータベースに対して発行し、結果を取得します。
SELECT
order_date AS "注文日",
SUM(sales) AS "売上",
COUNT(DISTINCT customer_id) AS "購買顧客数"
FROM orders
WHERE YEAR(order_date) = 2023
GROUP BY order_date上記のSQLの結果、データの利用者の元には以下のようなデータが渡り、可視化や分析に活用できるようになります。
| 日付 | 売上 | 購買顧客数 |
| 2023-01-01 | 123123 | 123 |
| 2023-01-02 | 234234 | 234 |
| 2023-01-03 | 345345 | 345 |
| … | … | … |
データ利用者が誰でもデータ集計・分析ができるようになったことでビジネスロジックへの解釈の差分により、ダッシュボードによって表示されている数値が異なるといった課題も発生するようになりました。例えば、とある部署が見てるダッシュボードでは、「売上」に返品額が反映されるのに、他の部署の人のレポートでは反映されないといった課題です。
また、データの活用が進んでいる組織では、データウェアハウスを参照するのはBIツールだけではありません。例えばデータサイエンティストは、Jupyer Notebookを使って分析するかもしれませんし、社内アプリケーションへの埋め込みを使って、データウェアハウスから直接データを取得し表示するレポートもあるかもしれません。
その度に、ロジックの定義やセマンティックレイヤーの構築が発生することは、ビジネスロジックの定義の分散を意味します。これでは、組織内のデータ活用が進めば進むほど、定義が分散してしまうリスクが発生してしまいます。更に、データの定義に変更が走った際にも、新しい定義が反映されているレポートと、反映されていないレポートなどが出てくるかも知れません。
ユニバーサル・セマンティックレイヤーは、データが利用される様々なサービス(各種BIツール、Notebook、アプリケーションなど)からAPIを経由して接続し、統合管理されたセマンティックレイヤーを使って、データウェアハウスにあるデータを集計することができます。
ユニバーサル・セマンティックレイヤーを提供する代表的なサービスにCube
Cubeでは、画像右側にあるような多種多様なアプリケーション(BIツール、埋め込み分析、ノートブックやその他App)から接続可能なセマンティックレイヤー(画像中央)を提供しています。接続先としてもSnowflakeやBigQueryなどの様々なデータウェアハウスへの接続をサポート(画面左側)しています。
これにより、各データ利用者が使い慣れたサービスやデータウェアハウスを利用したまま、表示されるデータの定義に対して信頼性を与える仕組みが実現できるようになりました。
更に、Cubeはロジックの管理だけではなく、データへのアクセス制御やパフォーマンス高速化させることや、SQL/REST/GraphQLなどの幅広いAPIへの対応も含めてサービス提供しています。
このように、従来型BIにあったロジック管理のスコープの狭さを解消しつつ、他にもデータ活用者にとって便利な様々な機能を提供するサービスはHeadless BIとも呼ばれています。
Headless BIを導入するメリット
Headless BIの導入によって、組織は以下のようなメリットを得ることが期待できます。
- データへの信頼性の向上
- パフォーマンスの向上、DWコストの節約
- データ民主化の加速
データへの信頼性の向上
まず最初に挙げられるのが、ビジネスロジックの統合管理によるデータの信頼性の向上です。
ロジックの定義をHeadless BIに寄せると、ビジネスロジックの分散を抑えることが期待できるため、組織がモニタリングするKPIに定義の揺れが発生するのを抑えることや、集計定義のバージョン管理や一括変更などが容易になります。
既存のETLツールなども、データウェアハウス内のテーブルやビューの定義を管理することはできますが、それらの完成されたテーブルやビューに対して、外部から投げられるSQLのロジックを管理するのは限界があります。Headless BIを活用することで、外部からデータウェアハウス内に構築済みのテーブル・ビューに対して投げられるクエリのロジックも含めて管理することが可能になります。
パフォーマンスの向上、DWコストの節約
実用的なメリットとしてクエリのパフォーマンス向上も期待できます。
例えば上記のCubeでは、インメモリキャッシュ(Request Cache)と、事前集計データ(Pre-aggregation Store)の2段階のクエリ高速化手段を提供しています。




