

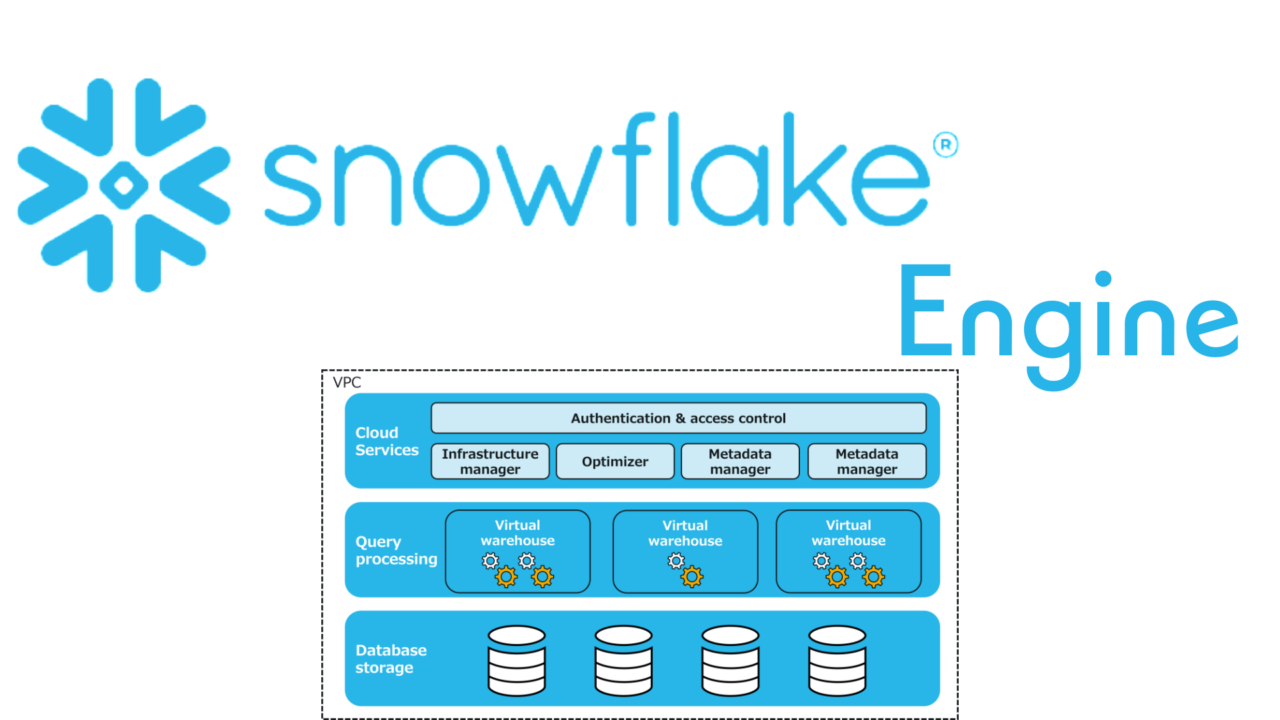
Snowflakeのアーキテクチャは Storage・Compute・Cloud Services の3層で構成されています。
① Storage Layer(ストレージ層:エンジンのデータ基盤)
- 列指向ストレージ
- 自動パーティション(Micro-Partition)
- 自動圧縮 / 自動暗号化
- データのレイアウト最適化
ユーザーはパーティション設計・圧縮設定などを一切行う必要なし。
これが“ゼロメンテナンスDWH”と言われる理由。
② Compute Layer(Virtual Warehouse:実行エンジン)
いわゆる Snowflakeのクエリ実行エンジンそのもの。
特徴:
- 仮想倉庫と呼ばれる独立した計算クラスター
- 任意サイズ(XS〜6XLなど)に拡張可能
- 自動スケール(Multi-Cluster)
- Auto-Suspend / Auto-Resume で自動停止・起動
- 複数ワークロードを隔離することが可能(ETL専用倉庫 / BI専用倉庫など)
他のDWHと違う点:
Computeがストレージと完全に分離しており、同じデータを複数のComputeで同時利用しても互いに干渉しない。
③ Cloud Services Layer(制御層:エンジンの頭脳)
Snowflakeが他DWHと根本的に違うのはこの層が存在すること。
役割:
- クエリ最適化(Query Optimizer)
- メタデータ管理
- トランザクション管理
- 認証・認可
- セキュリティポリシー(RLS、CLS、タグベース)
- SSO / IAM
- Time Travel / Fail-Safe 管理
- オブジェクト管理(スキーマ・テーブル・ビューなど)
つまり、Snowflakeの“エンジンの知性”はほぼこのCloud Servicesに存在する。
⭐ Snowflakeエンジンを理解する重要なポイント
① ストレージとコンピュートの完全分離
BigQuery・Redshift・Databricksなどとの違いはここにある。
- クエリの実行性能は Compute(Warehouse)で決まる
- データの保存方式は Storage が管理
- Cloud Services が両者をうまく仲介し最適化
結果:
スケールが速く、負荷に強く、同時利用にも強い。
② Micro-Partition × 自動最適化
Snowflakeは全データを Micro-partition という数MB単位のブロックで管理。
特徴:
- クエリに必要なパーティションだけをScan
- 自動的に統計を保持し、Optimizerが賢く選択
- Z-orderなどの手動チューニングが原則不要
→ これが “Snowflakeはチューニング不要” と言われる理由。
③ Query Optimizer(Snowflakeエンジンの核心)
Snowflakeは複雑な処理計画を自動生成します:
- パーティションPruning
- 自動JOIN最適化
- 自動クラスタリング
- 動的再最適化
- キャッシュ(結果キャッシュ・メタデータキャッシュ)
ユーザはSQLを書く以外に最適化を意識する必要なし。
④ サーバレス要素との連携(Snowpipe, Tasks, Streams)
これらは Snowflakeエンジンの一部として動作し、
データ処理を完全自動化できる:
- アップロードされたファイルを自動ロード(Snowpipe)
- 定期ジョブ(Tasks)
- CDC処理(Streams)
分析だけでなく、DWHによるデータパイプライン実行エンジンとしても機能。2




